

Self-Hosting Guide: Grafana Mimir im Monolithic Mode richtig skalieren
Erfahre wie du auch ohne Kubernetes, Grafana Mimir im Monolithic Mode skalierst mit Azure Container Apps, Consul und Memcached.

Einführung
In vielen realen Szenarien fehlt es an belastbaren Beispielen, wie sich Grafana Mimir im Monolithic Deployment Mode effektiv und stabil betreiben lässt. Besonders herausfordernd wird dies, wenn große Mengen an Metriken aus Prometheus-Umgebungen gesammelt, gespeichert und performant abgefragt werden sollen ohne auf eine vollständig orchestrierte Microservice-Architektur wie Kubernetes zurückgreifen zu können.
Dieser Artikel adressiert das Self-Hosting von Grafana Observability-Komponenten in Azure, außerhalb eines Kubernetes-Clusters, etwa in Compute Ressourcen wie Azure Container Apps oder Azure App Services. Der Fokus liegt auf einem produktionsnahen Setup mit kontrolliertem Ressourcenverbrauch, ohne auf die Skalierbarkeit und Modularität der Grafana Suite verzichten zu müssen.
Im Zentrum der Lösung steht die Grafana Observability Suite, die aus modularen Komponenten besteht, die sich sowohl einzeln als auch in Kombination betreiben lassen:
| Komponente | Verwendungszweck | Typischer Einsatzbereich |
|---|---|---|
| Grafana | Visualisierung | Dashboards, Alerts, Query-Editor für Metriken, Logs und Traces |
| Mimir | Speicherung und Abfrage von Metriken | Langzeitarchiv, Metrik-Backend für Prometheus |
| Loki | Zentrale Speicherung von Logs | Aggregation und Analyse verteilter Logdaten |
| Tempo | Distributed Tracing | Analyse von Latenzen und Service-Abhängigkeiten |
| Prometheus | Metrik-Scraping | Sammlung von Zeitreihendaten über Pull-Mechanismus |
| Pushgateway | Push-basierte Metrikerfassung | Übergabe kurzlebiger Metriken aus Batch- oder CI-Jobs |
| Alloy | Dynamische Datenerfassung | Konvergenter Agent mit konfigurierbaren Pipelines und zentralem Mgmt |
Im Fokus dieses Artikels steht Grafana Mimir als zentrales Speichersystem für Metriken innerhalb der Suite. Ziel ist es, eine robuste und wartbare Architektur aufzuzeigen, die auch ohne Kubernetes funktioniert. Insbesondere für Unternehmen oder Teams, die Azure-native Dienste bevorzugen und dennoch von der Leistungsfähigkeit von Mimir profitieren möchten.
Warum wird Mimir benötigt?
Der Bedarf an skalierbaren, hochverfügbaren Metriklösungen hat in den letzten Jahren erheblich zugenommen. Klassische Monitoring-Setups wie einzelne Prometheus-Instanzen bieten zwar eine solide Basis für die Datenerfassung, stoßen jedoch schnell an technische und operative Grenzen. Insbesondere bei wachsender Systemkomplexität, steigenden Abfragefrequenzen oder bei der Notwendigkeit, Metriken langfristig und redundant zu speichern ist das ein Problem.
Grafana Mimir schließt dabei genau die Lücke da es als zentrales Backend für Metriken fungiert. Mimir ermöglicht die horizontale Skalierung, unterstützt Redundanz, bietet Langzeitspeicherung über Jahre hinweg und liefert auch bei sehr großen Datenmengen eine hohe Query-Performance.
Im Zusammenspiel mit Prometheus agiert Mimir als langlebige Speicherlösung für Prometheus-Daten. Prometheus selbst ist bewusst schlank gehalten und nicht für langfristige Speicherung, Skalierung oder Ausfallsicherheit konzipiert. Mimir erweitert diese Fähigkeiten und macht Prometheus damit produktionsreif für Enterprise-Umgebungen. Doch Mimir ist nicht nur das Langzeit-Backend für Prometheus. Auch Daten aus dem Grafana Pushgateway lassen sich nahtlos in Mimir integrieren. Darüber hinaus liefert auch Alloy Metriken direkt an Mimir, oft ohne zwischengeschaltetes Prometheus.
Damit fungiert Mimir als zentraler Aggregationspunkt für nahezu alle quantitativen Datenquellen innerhalb der Grafana Observability Suite. Es speichert demzufolge:
- regelmäßig gescrapete Metriken aus Prometheus-Instanzen
- gepushte Metriken aus Pushgateway-Prozessen
- direkt gesendete Metriken aus Grafana Agent oder Alloy
Durch diese zentrale Rolle bietet Mimir nicht nur hohe Verfügbarkeit und Performance, sondern auch eine konsistente Datenbasis, auf der Visualisierung, Alerting und Analyse zuverlässig aufbauen können.
Deployment Modes
Grafana Mimir ist so konzipiert, dass es sich flexibel an verschiedene Infrastrukturen und Betriebsmodelle anpassen lässt. Abhängig von Skalierungsbedarf, Betriebserfahrung und Infrastrukturvorgaben kann Mimir in unterschiedlichen Deployment-Modes betrieben werden.
Mimir unterstützt aktuell zwei offizielle Deployment-Varianten. Jede dieser Varianten ist für spezifische Einsatzzwecke optimiert:
| Modus | Beschreibung | Zielgruppe / Use Case |
|---|---|---|
| Monolithic | Alle Komponenten laufen in einem einzelnen Prozess bzw. Container. | Einfaches Setup für kleinere Umgebungen oder Tests |
| Microservices | Jede Komponente ist ein eigenständiger Dienst, einzeln skalierbar. | Hochskalierbare, produktive Enterprise-Deployments |
Für viele produktionsnahe, nicht-Kubernetes-basierte Deployments (bspw. in Azure Container Apps oder VMs) bietet der Monolithic Mode eine ideale Balance zwischen Einfachheit und Funktionalität. In dieser Variante lassen sich mit wenig Infrastruktur alle Core-Komponenten betreiben und ist ideal für dedizierte Setups ohne komplexes Service-Mesh.
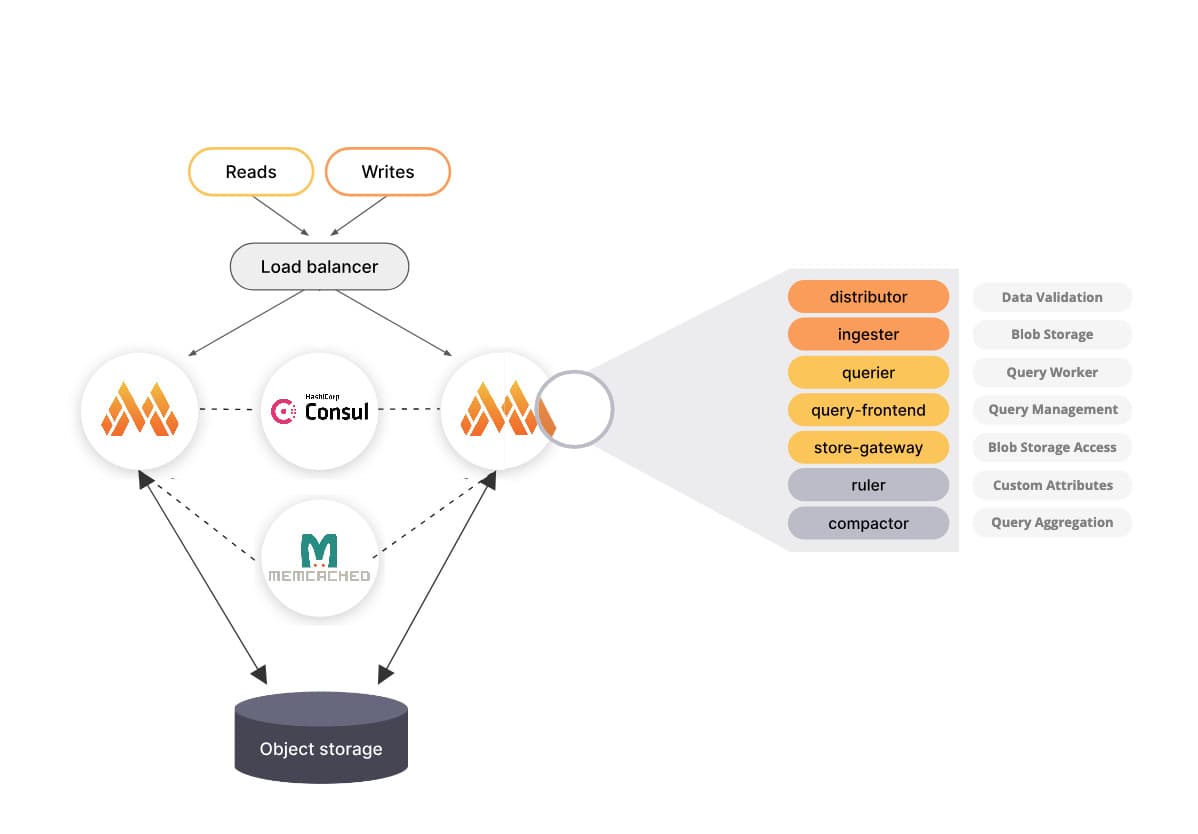
Im Folgenden ist der Monolithic Mode auf hoher Flugebene dargestellt:

Der Monolithic Mode von Mimir kann horizontal skaliert werden. Im Folgenden ist ebenso aus der Mimir Dokumentation
die Visualisierung entnommen worden. Im Verlauf dieses Blog-Beitrags werde ich ebenso eine spezifisches Schaubild darstellen,
dass ebenso die Verwendung von Consul und Memchached integriert.

Der Microservice Mode wird in diesem Blog-Artikel nicht behandelt, da bereits wirklich gute Fallbeispiele und Vorlagen
im Rahmen eines Kubernetes existieren. Dazu sind am Ende des Blog-Beitrags weiterführende Ressourcen hinterlegt.

Komponenten von Mimir
Unabhängig vom Deployment-Modus basiert Mimir auf einer modularen Architektur. Jeder Bestandteil ist für einen klar abgegrenzten Aufgabenbereich zuständig. Im Folgenden ein Überblick über die zentralen Komponenten und ihre jeweiligen Funktionen.
Ingester
Der Ingester ist eine zentrale Komponente im Schreibpfad von Mimir. Er empfängt Zeitreihendaten vom Distributor, speichert sie temporär im Speicher und schreibt sie periodisch in den konfigurierten Objektspeicher. Dieser Prozess ermöglicht eine effiziente Entkopplung von Ingestion und Storage.
Die Hauptfunktionen sind dabei:
- Datenpufferung und Persistierung: Der Ingester speichert eingehende Metriken zunächst im Speicher und schreibt sie periodisch in Form von TSDB-Blöcken in den Objektspeicher. Dies reduziert die Schreiblast auf den Langzeitspeicher und verbessert die Systemleistung.
- Replikation: Zur Sicherstellung der Datenverfügbarkeit repliziert der Ingester eingehende Daten auf mehrere Instanzen. Dies gewährleistet, dass bei Ausfall einer Instanz keine Daten verloren gehen.
- Zusammenarbeit mit anderen Komponenten: Der Ingester arbeitet eng mit dem Distributor zusammen, der die eingehenden Daten validiert und an die entsprechenden Ingester verteilt. Zudem interagiert er mit dem Store-Gateway, um persistierte Daten für Abfragen bereitzustellen.
- Circuit Breakers: Um den Ingester vor übermäßiger Belastung durch langsame Schreib- oder Leseanfragen zu schützen, implementiert Mimir Circuit Breakers. Diese überwachen die Anzahl fehlgeschlagener Anfragen und können bei Überschreitung definierter Schwellenwerte neue Anfragen temporär ablehnen, um die Systemstabilität zu gewährleisten.
- Ressourcenbasiertes Read Path Limiting: Der Ingester kann so konfiguriert werden, dass er Leseanfragen basierend auf CPU- und Speicherverbrauch limitiert. Wenn die Ressourcenauslastung bestimmte Schwellenwerte überschreitet, werden neue Leseanfragen abgelehnt, um die Schreibpfade zu priorisieren und die Systemstabilität zu wahren.
- Spread-Minimizing Token Allocation: Zur gleichmäßigen Verteilung der Last verwendet Mimir eine optimierte Token-Zuweisungsstrategie im Hash-Ring. Diese "Spread-Minimizing Tokens" sorgen dafür, dass die Zeitreihendaten gleichmäßig auf die Ingester verteilt werden, was zu einer besseren Ressourcenauslastung und Systemleistung führt.
Distributor
Der Distributor ist eine zustandslose Komponente, die eingehende Zeitreihendaten von Prometheus oder Grafana Alloy empfängt. Er validiert die Daten auf Korrektheit und stellt sicher, dass sie innerhalb der konfigurierten Grenzen für einen bestimmten Mandanten liegen. Anschließend teilt der Distributor die Daten in Batches auf und sendet sie parallel an mehrere Ingester. Dabei werden die Serien unter den Ingestern aufgeteilt und jede Serie gemäß dem konfigurierten Replikationsfaktor repliziert. Standardmäßig beträgt der Replikationsfaktor drei.
Die Hauptfunktionen sind dabei:
- Datenvalidierung: Überprüft eingehende Daten auf Korrektheit und Einhaltung von Grenzwerten.
- Sharding und Replikation: Teilt Daten auf mehrere Ingester auf und repliziert sie entsprechend dem Replikationsfaktor.
- Stateless Design: Ermöglicht horizontale Skalierung und einfache Wiederherstellung bei Ausfällen.
Querier
Der Querier ist ebenso eine zustandslose Komponente, die PromQL-Ausdrücke auswertet, indem sie Zeitreihen und Labels im Lesepfad abruft. Der Querier verwendet die Store-Gateway-Komponente, um auf den Langzeitspeicher zuzugreifen und die Ingester-Komponente, um kürzlich geschriebene Daten abzufragen.
Die Hauptfunktionen sind dabei:
- PromQL-Auswertung: Führt komplexe Abfragen über aktuelle und historische Daten aus.
- Datenaggregation: Kombiniert Daten aus verschiedenen Quellen für umfassende Analysen.
- Skalierbarkeit: Unterstützt horizontale Skalierung zur Bewältigung hoher Abfragelasten.
Query Frontend
Das Query Frontend ist eine Komponente, die eingehende Abfragen empfängt und optimiert. Es teilt lange Abfragen in kleinere Zeitintervalle auf, prüft den Ergebniscache und verwendet bei Bedarf Sharding, um die Abfragen weiter zu parallelisieren. Anschließend stellt es die Abfragen in eine In-Memory-Warteschlange, aus der Queriers sie zur Ausführung abrufen.
Die Hauptfunktionen sind dabei:
- Abfrageoptimierung: Teilt lange Abfragen auf und ermöglicht parallele Verarbeitung.
- Caching: Speichert Abfrageergebnisse zur Reduzierung der Latenz bei wiederholten Abfragen.
- Warteschlangenmanagement: Verwaltet die Verteilung von Abfragen an Queriers zur Lastverteilung.
Query Scheduler (optional)
Der Query Scheduler ist eine optionale, zustandslose Komponente, die eine Warteschlange von auszuführenden Abfragen verwaltet und die Arbeitslast an verfügbare Queriers verteilt.
Die Hauptfunktionen sind dabei:
- Abfrageverteilung: Koordiniert die Zuweisung von Abfragen an Queriers.
- Skalierbarkeit: Ermöglicht die Skalierung von Query Frontends durch Entkopplung der Warteschlange.
- Service Discovery: Unterstützt DNS- und Ring-basierte Service Discovery für flexible Integration.
Compactor
Der Compactor erhöht die Abfrageleistung und reduziert die Nutzung des Langzeitspeichers, indem er Blöcke zusammenführt.
Die Hauptfunktionen sind dabei:
- Blockkomprimierung: Kombiniert mehrere Blöcke eines Mandanten zu einem optimierten größeren Block, was zu deduplizierten Chunks und einer reduzierten Indexgröße führt.
- Bucket-Index-Aktualisierung: Hält den Bucket-Index pro Mandant aktuell, der von Queriers, Store-Gateways und Rulern verwendet wird, um neue und gelöschte Blöcke im Speicher zu entdecken.
- Datenaufbewahrung: Löscht Blöcke, die außerhalb eines konfigurierbaren Aufbewahrungszeitraums liegen.
Store Gateway
Das Store Gateway ist eine zustandsbehaftete Komponente, die Blöcke aus dem Langzeitspeicher abruft. Im Lesepfad verwenden der Querier und der Ruler das Store Gateway beim Umgang mit Abfragen, unabhängig davon, ob die Abfrage von einem Benutzer stammt oder bei der Auswertung einer Regel erfolgt.
Die Hauptfunktionen sind dabei:
- Blockabfrage: Ruft relevante Datenblöcke aus dem Langzeitspeicher ab.
- Indexverwaltung: Hält einen aktuellen Überblick über verfügbare Blöcke und deren Metadaten.
- Sharding und Replikation: Unterstützt die horizontale Skalierung durch Aufteilung und Replikation von Blöcken über mehrere Instanzen.
Ruler
Der Ruler ist eine optionale, aber essenzielle Komponente in Grafana Mimir, die für die Ausführung von Recording- und Alerting-Regeln verantwortlich ist. Er ermöglicht es, aggregierte Metriken zu erstellen und Alarme basierend auf definierten Bedingungen auszulösen.
Die Hauptfunktionen sind dabei:
- Ausführung von Regeln: Der Ruler führt sowohl Recording- als auch Alerting-Regeln aus, die in Prometheus-kompatiblen Formaten definiert sind.
- Multi-Tenancy: Unterstützt die gleichzeitige Ausführung von Regeln für mehrere Tenants, wobei jeder Tenant seine eigenen Regelgruppen verwalten kann.
- Sharding: Zur horizontalen Skalierung teilt der Ruler die Ausführung von Regeln durch Sharding auf, wobei Regelgruppen auf verschiedene Ruler-Instanzen verteilt werden.
Der Ruler kann in zwei Betriebsmodi konfiguriert werden:
- Interner Modus: Der Standardmodus bei dem der Ruler direkt mit den Ingester- und Querier-Komponenten kommuniziert, um Daten zu lesen und zu schreiben.
- Remote Modus: In diesem Modus delegiert der Ruler die Ausführung von Regeln an separate Query-Komponenten, was eine bessere Skalierbarkeit und Isolation ermöglicht.
Die Verwaltung von Regeln kann auf verschiedene Weisen erfolgen:
- HTTP API: Ermöglicht das Erstellen, Aktualisieren und Löschen von Regelgruppen über RESTful-Endpunkte.
- Mimirtool CLI: Ein Befehlszeilentool, das Funktionen zum Linting, Formatieren und Hochladen von Regeln bietet.
Der Ruler unterstützt verschiedene Speicher-Backends für die Speicherung von Regeln:
- Objektspeicher: Unterstützt Amazon S3, Google Cloud Storage, Azure Blob Storage und OpenStack Swift.
- Lokaler Speicher: Liest Regeln aus dem lokalen Dateisystem; dieser Modus ist jedoch schreibgeschützt und unterstützt keine API-basierten Änderungen.
Skalierung des Monolithic Deployment Mode
Der Monolithic Deployment Mode von Grafana Mimir ermöglicht es, alle Kernkomponenten in einem einzigen Prozess oder Container auszuführen. Dies vereinfacht die Bereitstellung erheblich, insbesondere in Umgebungen ohne Kubernetes oder komplexe Orchestrierungssysteme.
Obwohl der Monolith-Modus eine vereinfachte Bereitstellung bietet, existiert keine offizielle, produktionsreife Standardkonfiguration für diesen Modus. Die offizielle Dokumentation bietet lediglich eine Beispielkonfiguration für Demonstrationszwecke, die nicht für den produktiven Einsatz geeignet ist.
Der Monolith-Modus eignet sich besonders für:
- Entwicklungs- und Testumgebungen: Schnelles Aufsetzen und einfache Handhabung.
- Kleinere Produktionsumgebungen: Wo die Anforderungen an Skalierbarkeit und Hochverfügbarkeit begrenzt sind.
- Umgebungen ohne Kubernetes: Einsatz in traditionellen VM-basierten Infrastrukturen oder Azure Managed Compute Ressourcen.
Architektur unseres Mimir-Setups
Unser Mimir-Setup besteht aus einem einzelnen, konsolidierten Container, der alle zentralen Mimir-Komponenten beinhaltet bspw. Distributor, Ingester, Querier, Store Gateway, Ruler, Compactor, Alertmanager, Query Frontend und Scheduler. Diese Architektur erlaubt uns, Mimir auch in containerisierten Azure-Plattformen wie Azure Container Apps oder App Services zu betreiben.
Zur Unterstützung der Hochverfügbarkeit und Performance des Monolithen setzen wir auf folgende zusätzliche Dienste und Komponenten:
- Azure Blob Storage: Dient als zentraler Objekt-Storage für alle persistierten Metriken, Alertmanager-Daten und Ruler-States. Mimir nutzt hier dedizierte Container für unterschiedliche Datenklassen (Blocks, Alertmanager, Ruler).
- Memcached (Self-Hosted): Integriert zur Beschleunigung von Metadaten-, Chunk- und Index-Cache-Zugriffen sowie für die Query-Result- und Ruler-Caches. Durch Caching auf Anwendungsebene wird die Last auf den Blob Storage reduziert und die Antwortzeit für komplexe PromQL-Abfragen verbessert.
- Consul (Self-Hosted): Fungiert als zentrales Key-Value-Store-Backend für sämtliche Sharding- und Ring-Strukturen in Mimir. Komponenten wie Ingester, Store Gateway, Alertmanager oder Query Scheduler nutzen Consul zur Service-Discovery, Lastverteilung und Replikationssteuerung.
Die einzelnen Mimir-Komponenten laufen gemeinsam in einem Containerprozess, kommunizieren über lokale Schnittstellen und koordinieren sich über konsistente Hash-Ringe, die durch Consul verwaltet werden. Persistente Datenströme wie Zeitreihenschreiboperationen und Rule-Recording-Ausgaben landen in Azure Blob Storage. Der Cache der Memcached Instanz sorgt dafür, dass wiederholte Zugriffe auf die selben Daten effizient abgebildet werden können. Die Query-Pfade sind so konzipiert, dass das Query Frontend eingehende Anfragen aufteilt, verteilt und über den Query Scheduler organisiert. Der Scheduler erkennt dabei verschiedene Abfragetypen und sorgt für optimale Ressourcenverteilung.
Vorteile dieses Setups:
- Kompakter Betrieb ohne komplexe Orchestrierung oder verteilte Service-Netzwerke
- Skalierbare Performance durch Caching, Sharding und Entkopplung von Storage und Compute
- Azure-native Integration durch die Nutzung von Blob Storage, Containerized Deployment und Service-Discovery über externe, mit Azure kompatiblen Tools
- Einfache Wartung und Upgrades, da alle Komponenten in einem Prozess gebündelt sind
Diese Architektur eignet sich besonders für Teams oder Unternehmen, die:
- Keine Kubernetes-Infrastruktur betreiben, aber trotzdem moderne Observability-Lösungen einsetzen wollen
- Eine überschaubare Anzahl von Metrikproduzenten haben (bspw. via Prometheus, Pushgateway, Grafana Agent oder Alloy)
- Ein kosteneffizientes, aber produktionsfähiges Monitoring-Backend benötigen
- Ihre Workloads vollständig in Azure betreiben und dort Containerlösungen bevorzugen
In der folgenden Darstellung ist unser finales Setup dargestellt. Dabei nutzen wir mehrere Mimir Instanzen im Monolithic
Mode und koordinieren diese über eine dedizierte Consul Instanz. Um wiederkehrende Queries und Daten zu cachen integrieren
wie zudem Memcached in unser Setup.
Konfiguration des Container App Environments
In Rahmen dieses Blog-Artikels deployen wir drei unterschiedliche Container Apps in einem Container App Environment. Dabei deployen wir eine Container App jeweils für Consul, Memcached und Mimir. Durch die Möglichkeit Replikas zu konfigurieren, können wir nachträglich je nach Bedarf entweder mit Scaling Rules oder durch eine feste Anzahl an Mimir Instanzen die erforderlichen Ressourcen anpassen.
Um unser Setup erfolgreich umzusetzen, deployen wir in unserem VNet ein Container App Environment und ein Private Endpoint Subnet, um verschlüsselt und über den Azure Backbone direkt auf den Key Vault und Storage Account für unsere Mimir Container App zuzugreifen.
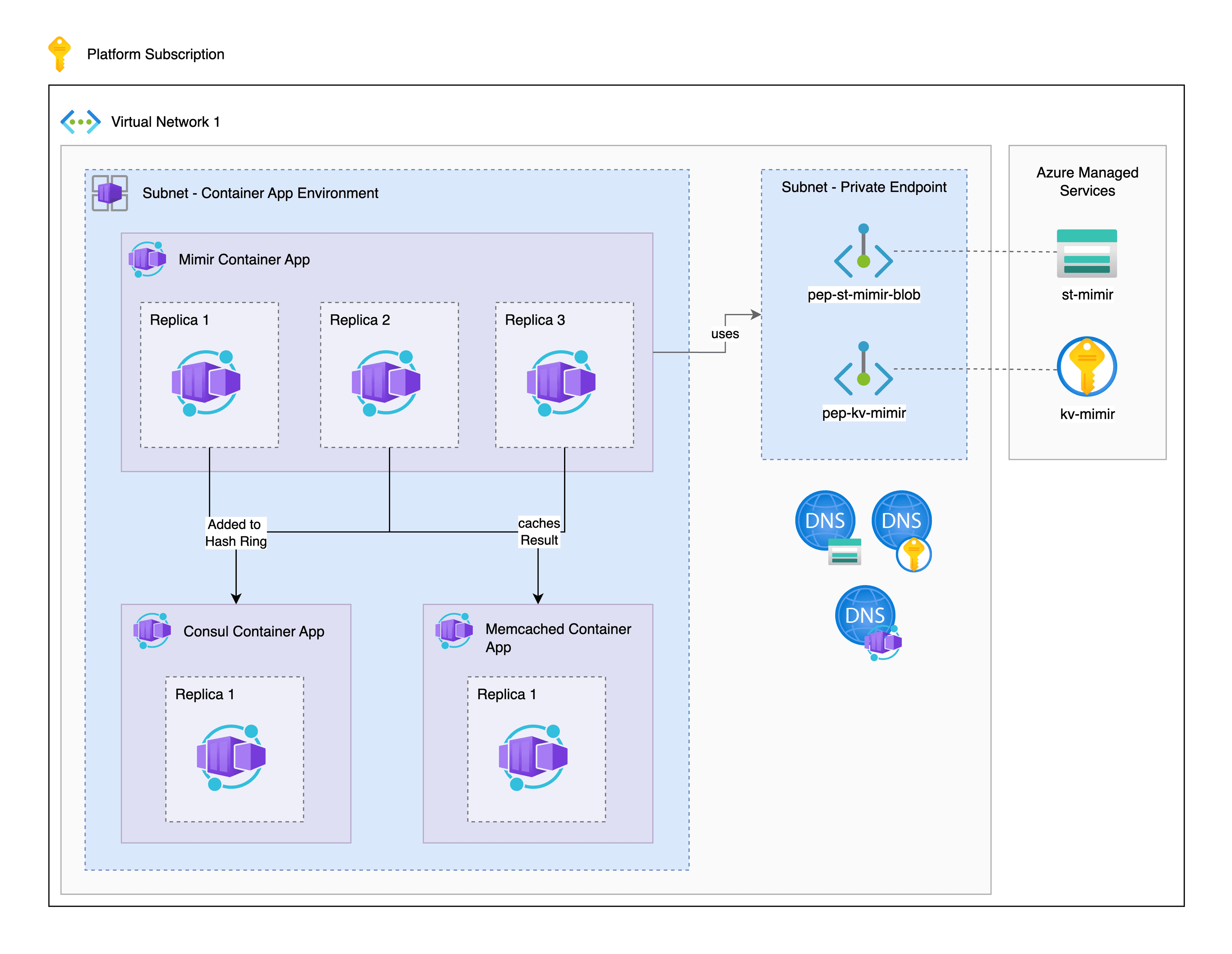
Deployment der Support Ressourcen
Damit wir unser Setup nun erfolgreich deployen können, möchte ich nun auf die jeweiligen Konfigurationen und Dockerfiles eingehen. Für Memcached und Consul nutze ich dabei für Demonstrationszwecken die mögliche Minimalkonfiguration. Bitte berücksichte für dein individuelles Setup, ob du Memcached oder Consul nutzen möchtest und welche Funktionen von Mimir du tatsächlich benötigst.
Die Dockerfiles in diesem Blog-Artikel besitzen bereits einzelne CVE fixes, jedoch können in der Zwischenzeit bereits
neue CVEs in den Dockerfiles enthalten sein. Aus diesem Grund überprüfe bitte vor einem produktiven Deployment, ob
neue Findings vorhanden sind. Du kannst dazu bspw. den Befehl trivy image (image-sha hier verwenden) nutzen.
Deployment von Memcached
In diesem Setup nutzen wir ein kompaktes Memcached Dockerfile bei dem wir den Port 11211 für Memcached exposen.
FROM memcached:latest
EXPOSE 11211
CMD ["memcached"]
Deployment von Consul
Für die Verwendung von Consul habe ich statt dem public Image, ein Custom Image hinterlegt, da das aktuellste Image im Docker Hub leider vereinzelte Critical Findings beinhaltet. Dieses Custom Image orientiert sich dabei am generischen Dockerfile im Hashicorp Consul Repository. -> Link zur Referenz
Falls du kein Custom Image verwenden möchtest und die Critical Finding in deinem Fall nicht relevant sind, kannst du gerne auch das offizielle Consul Image verwenden. Du musst dabei nur beachten den Port 8301 und 8500 zu exposen.
# Dockerfile for Consul 1.20.6
FROM alpine:3.21 AS builder
# Consul version
ARG VERSION=1.20.6
# HashiCorp Releases URL
ENV HASHICORP_RELEASES=https://releases.hashicorp.com
# Install necessary packages
RUN apk add --no-cache \
ca-certificates \
curl \
dumb-init \
gnupg \
libcap \
su-exec \
iputils \
jq \
libc6-compat \
openssl \
iptables \
tzdata \
unzip
# Create consul user and group
RUN addgroup consul && adduser -S -G consul consul
# Download and verify Consul binary
RUN set -eux; \
apkArch="$(apk --print-arch)"; \
case "${apkArch}" in \
aarch64) consulArch='arm64' ;; \
armhf) consulArch='arm' ;; \
x86) consulArch='386' ;; \
x86_64) consulArch='amd64' ;; \
*) echo >&2 "error: unsupported architecture: ${apkArch}" && exit 1 ;; \
esac; \
mkdir -p /tmp/build; \
cd /tmp/build; \
curl -O ${HASHICORP_RELEASES}/consul/${VERSION}/consul_${VERSION}_linux_${consulArch}.zip; \
curl -O ${HASHICORP_RELEASES}/consul/${VERSION}/consul_${VERSION}_SHA256SUMS; \
curl -O ${HASHICORP_RELEASES}/consul/${VERSION}/consul_${VERSION}_SHA256SUMS.sig; \
gpg --keyserver keyserver.ubuntu.com --recv-keys C874011F0AB405110D02105534365D9472D7468F; \
gpg --batch --verify consul_${VERSION}_SHA256SUMS.sig consul_${VERSION}_SHA256SUMS; \
grep consul_${VERSION}_linux_${consulArch}.zip consul_${VERSION}_SHA256SUMS | sha256sum -c; \
unzip consul_${VERSION}_linux_${consulArch}.zip; \
cp consul /bin/consul; \
cd /; \
rm -rf /tmp/build; \
gpgconf --kill all; \
apk del gnupg openssl; \
rm -rf /root/.gnupg
# Tiny smoke test
RUN consul version
# Final minimal image
FROM alpine:3.21
LABEL org.opencontainers.image.authors="Consul Team <consul@hashicorp.com>" \
org.opencontainers.image.url="https://www.consul.io/" \
org.opencontainers.image.documentation="https://www.consul.io/docs" \
org.opencontainers.image.source="https://github.com/hashicorp/consul" \
org.opencontainers.image.version="1.20.6" \
org.opencontainers.image.vendor="HashiCorp" \
org.opencontainers.image.title="consul" \
org.opencontainers.image.description="Consul is a datacenter runtime..."
# Install runtime dependencies
RUN apk add --no-cache \
dumb-init \
libc6-compat \
iptables \
tzdata \
ca-certificates \
iputils \
libcap \
su-exec \
jq
# Create consul user and group
RUN addgroup consul && adduser -S -G consul consul
# Copy consul binary
COPY --from=builder /bin/consul /bin/consul
# Setup required directories
RUN mkdir -p /consul/data /consul/config && \
chown -R consul:consul /consul
VOLUME /consul/data
# Ports
EXPOSE 8300 8301 8301/udp 8302 8302/udp 8500 8600 8600/udp
# Set up nsswitch.conf for Go's netgo DNS
RUN test -e /etc/nsswitch.conf || echo 'hosts: files dns' > /etc/nsswitch.conf
# Copy entrypoint
COPY docker-entrypoint.sh /usr/local/bin/docker-entrypoint.sh
RUN chmod +x /usr/local/bin/docker-entrypoint.sh
ENTRYPOINT ["docker-entrypoint.sh"]
CMD ["agent", "-dev", "-client", "0.0.0.0"]
# docker-entrypoint.sh
#!/bin/sh
set -e
# If running as root, run Consul as the consul user
if [ "$(id -u)" = '0' ]; then
exec consul "$@"
fi
exec "$@"
Die verwendeten Mimir Komponenten
In diesem Kapitel möchte ich erläutern wie die zentrale Konfiguration für den Betrieb von Grafana Mimir im Monolithic Deployment Mode auf einer Azure-basierten Infrastruktur umgesetzt werden kann. Dazu möchte ich zunächst die einzelnen Konfigurationsparameter erläutern.
Gemeinsame Storage-Konfiguration (common.storage)
Die Speicherung aller persistierten Daten erfolgt über Azure Blob Storage. Hierbei wird der Objektspeicher explizit als Backend definiert. Die Konfiguration umfasst:
- Account Name und Key: Authentifizierung gegenüber Azure Blob Storage
- Endpoint Suffix: Angabe des Azure Endpunkts (blob.core.windows.net)
Dadurch kann Mimir große Mengen an Zeitreihendaten dauerhaft und zuverlässig in Azure zu speichern, ohne lokalen Speicherbedarf.
Block Storage Konfiguration (blocks_storage)
Hier wird spezifiziert, wo Mimir Zeitreihendaten ablegt und wie es diese effizient cached:
- Container Name: Alle TSDB-Blöcke werden in den Azure-Container mimirblocks geschrieben.
- Caches (Index, Chunks, Metadaten):
- Nutzung von Memcached als Cache-Backend
- Separate Konfiguration für Index-Cache, Chunk-Cache und Metadaten-Cache
- Maximalgrößen und Timeouts sind so gewählt, dass eine hohe Cache-Effizienz gewährleistet bleibt
Der Caching-Layer reduziert die Zugriffslast auf Azure Blob Storage erheblich und sorgt für eine niedrigere Latenz bei Abfragen.
Alertmanager Storage (alertmanager_storage)
Der Zustand des Alertmanagers (aktive Alerts, Silences, etc.) wird ebenfalls persistiert. So wird sichergestellt, dass Alerts über Container-Neustarts hinweg erhalten bleiben.
- Nutzung des Azure Containers: mimir-alertmanager
Ruler Storage (ruler_storage)
Für die Speicherung von Recording- und Alerting-Regeln wird ein separater Container in Azure genutzt:
- Azure Container: mimir-ruler
- Cache für Ruler-Abfragen: Wieder Memcached zur Beschleunigung der Rule-Auswertung Dadurch bleiben Rule States und Ergebnisse über längere Laufzeiten konsistent und performant abrufbar.
Servereinstellungen (server)
Log Level: debug, um umfassende Informationen während des Betriebs und für Troubleshooting einzusehen.
- HTTP Listen Port: 9009 ist der Standardport für alle internen und externen API-Endpunkte von Mimir. Diese API werden wir später noch benötigen.
Multitenancy
In diesem Setup wird Mimir single-tenant betrieben, sodass es keine Tenant-Isolation gibt. Diese Konfiguration ist bewusst gewählt, da sie in vielen Azure-Umgebungen die Komplexität reduziert und ein einfacheres User- und Query-Management ermöglicht.
- Multitenancy Disabled: multitenancy_enabled: false
Limits
Cache Unaligned Requests: Aktiviert, um auch bei unvollständig indexierten Daten auf Caching-Mechanismen zurückzugreifen und damit die Systemperformance weiter zu erhöhen.
Sharding und Ring Management
Sämtliche sharding-fähigen Komponenten (z. B. Alertmanager, Compactor, Distributor, Ingester, Store Gateway, Query Scheduler, Ruler) verwenden:
- Consul als zentrales Key-Value-Backend
- Service Discovery über Ring-Verwaltung
Dadurch wird sichergestellt, dass Mimir selbst im Monolith-Modus eine echte Lastverteilung realisiert und Störungen einzelner Komponenten auffangen kann.
Frontend-Optimierungen (frontend)
Das Query Frontend ist so konfiguriert, dass Anfragen möglichst effizient verarbeitet werden:
- Split Queries by Interval: Teilt große Zeitabfragen automatisch in kleinere Sub-Abfragen auf
- Sharding aktiver Series-Queries: Aktiviert zur besseren Lastverteilung
- Parallelisierung von shardbaren Queries: Um die Query-Latenz weiter zu reduzieren
- Results Cache: Caching der Query-Ergebnisse über Memcached zur Entlastung der Querier-Prozesse
Diese Konfiguration ist entscheidend für eine schnelle, ressourcenschonende Verarbeitung großer PromQL-Abfragen, insbesondere bei hoher Benutzeraktivität.
Konfiguration von Mimir
Um Mimir nun entsprechend des vorhergehenden Kapitels zu konfigurieren, müssen wir eine mimir.yml Datei erstellen. Dabei kannst du für die Verwendung von Azure Blob Storage, Consul und Memcached die folgende Konfiguration verwenden.
# mimir.yml
---
common:
storage:
backend: azure
azure:
account_key: AZURE_ACCOUNT_KEY
account_name: AZURE_ACCOUNT_NAME
endpoint_suffix: "blob.core.windows.net"
blocks_storage:
azure:
container_name: "mimirblocks"
bucket_store:
index_cache:
backend: "memcached"
memcached:
addresses: AZURE_MEMCACHED_FQDN
max_item_size: 5242880
timeout: 5s
chunks_cache:
backend: "memcached"
memcached:
addresses: AZURE_MEMCACHED_FQDN
max_item_size: 1048576
timeout: 5s
metadata_cache:
backend: "memcached"
memcached:
addresses: AZURE_MEMCACHED_FQDN
max_item_size: 1048576
alertmanager_storage:
azure:
container_name: "mimir-alertmanager"
ruler_storage:
azure:
container_name: "mimir-ruler"
cache:
backend: "memcached"
memcached:
addresses: AZURE_MEMCACHED_FQDN
server:
log_level: debug
http_listen_port: 9009
multitenancy_enabled: false
limits:
cache_unaligned_requests: true
alertmanager:
sharding_ring:
kvstore:
store: consul
consul:
host: AZURE_CONSUL_FQDN
compactor:
sharding_ring:
kvstore:
store: consul
consul:
host: AZURE_CONSUL_FQDN
frontend:
split_queries_by_interval: 12h
shard_active_series_queries: true
parallelize_shardable_queries: true
additional_query_queue_dimensions_enabled: true
cache_results: true
results_cache:
backend: "memcached"
memcached:
addresses: AZURE_MEMCACHED_FQDN
max_item_size: 1048576
timeout: 5s
query_scheduler:
service_discovery_mode: "ring"
additional_query_queue_dimensions_enabled: true
ring:
kvstore:
store: consul
consul:
host: AZURE_CONSUL_FQDN
distributor:
ring:
kvstore:
store: consul
consul:
host: AZURE_CONSUL_FQDN
ingester:
ring:
kvstore:
store: consul
consul:
host: AZURE_CONSUL_FQDN
store_gateway:
sharding_ring:
kvstore:
store: consul
consul:
host: AZURE_CONSUL_FQDN
ruler:
ring:
kvstore:
store: consul
consul:
host: AZURE_CONSUL_FQDN
In unserer mimir.yml Datei haben wir mehrere Placeholder wie AZURE_ACCOUNT_KEY, AZURE_ACCOUNT_NAME, AZURE_MEMCACHED_FQDN und AZURE_CONSUL_FQDN. Diese Parameter wollen wir dynamisch über Umgebungsvariablen in die mimir.yml einsetzen. Dazu existiert ein startup.sh Skript, dass diese Parameter einsetzt.
Im Startup Skript wird zudem parallel zur Mimir Instanz der Nginx Load-Balancer gestartet.
Ein Punkt der dich in diesem Setup sehr viel Nerven kosten kann, ist das Default-Verhalten beim Startup von Mimir.
In der Regel kannst du mit -target=all alle erforderlichen Mimir-Komponenten starten. Jedoch ist dieser Flag
irreführend, da tatsächlich nicht alle Komponenten gestartet werden.
Im folgenden -> Github Issue ist das Problem ausführlich dargestellt.
Dieses Problem ist bereits etwas Länger bekannt und kann ebenfalls in -> diesem Thread
eingesehen werden.
Im Github Issue werden alle Komponenten, die beim flag -target=all gestartet werden, wie folgt beschrieben:
Modules marked with * are included in target All:
alertmanagerallcompactor *distributor *flusheringester *overrides-exporterpurger *querier *query-frontend *query-schedulerruler *store-gateway *
In unserem Setup wollen wir ebenso die query-scheduler Komponente verwenden und aus diesem Grund aktivieren wir diesen explizit im Startup-Skript.
# startup.sh
#!/bin/sh
echo "YAML file update started."
yaml_file="/etc/mimir/mimir.yml"
if [ -z "$AZURE_ACCOUNT_KEY" ]; then
echo "ERROR: AZURE_ACCOUNT_KEY environment variable is not set or empty."
exit 1
fi
if [ -z "$AZURE_ACCOUNT_NAME" ]; then
echo "ERROR: AZURE_ACCOUNT_NAME environment variable is not set or empty."
exit 1
fi
if [ -z "$AZURE_CONSUL_FQDN" ]; then
echo "ERROR: AZURE_CONSUL_FQDN environment variable is not set or empty."
exit 1
fi
if [ -z "$AZURE_MEMCACHED_FQDN" ]; then
echo "ERROR: AZURE_MEMCACHED_FQDN environment variable is not set or empty."
exit 1
fi
sed -i "s/AZURE_ACCOUNT_KEY/$(echo "$AZURE_ACCOUNT_KEY" | sed 's/[\/&]/\\&/g')/g" "$yaml_file"
sed -i "s/AZURE_ACCOUNT_NAME/$(echo "$AZURE_ACCOUNT_NAME" | sed 's/[\/&]/\\&/g')/g" "$yaml_file"
sed -i "s/AZURE_CONSUL_FQDN/$(echo "$AZURE_CONSUL_FQDN" | sed 's/[\/&]/\\&/g')/g" "$yaml_file"
sed -i "s/AZURE_MEMCACHED_FQDN/$(echo "$AZURE_MEMCACHED_FQDN" | sed 's/[\/&]/\\&/g')/g" "$yaml_file"
echo "YAML file updated with environment variables."
echo "*** 1. Starting Nginx ***"
nginx
echo "*** 2. Starting Mimir ***"
/bin/mimir -config.file=/etc/mimir/mimir.yml -target=all,query-scheduler
In diesem Setup ist Mimir lediglich über Basic Authentication abgesichert. Dazu musst du deine nginx.conf Datei entsprechend anpassen und den jeweiligen Benutzernamen und dein in Base64 verschlüsseltes Password festlegen. In diesem Beispiel nutzen wir eine htpasswd Datei, jedoch solltest du im Produktivbetrieb diese sensiblen Daten aus einem Key-Vault heraus verwalten und als Umgebungsvariable im Dockerfile referenzieren.
Für diesen Abschnitt kannst du gerne die üblichen Nginx Vorlagen verwenden. In diesem Setup wird der Traffic stets zunächst über den Nginx an den Mimir Port weitergeleitet. Damit können wir sicherstellen, dass nur authentifizierte Personen auf unsere Mimir Instanz zugreifen.
# Mimir Dockerfile
FROM alpine:3.21.3 AS builder
# Kopiere die Konfigurationsdateien ins Build-Image
COPY startup.sh /etc/startup.sh
COPY mimir.yml /etc/mimir/mimir.yml
COPY nginx.conf /etc/nginx/nginx.conf
COPY htpasswd /etc/nginx/authnginx/htpasswd
RUN apk update && \
apk add --no-cache nginx bash curl && \
chmod +x /etc/startup.sh
# Stage 2: Extrahiere die Mimir Binary aus dem initialen Build-Image
FROM grafana/mimir:2.15.2 AS mimir-binary
# Stage 3: Konfiguriere unser finales Image inkl. NGINX and Mimir
FROM alpine:3.21.3
RUN apk update && \
apk add --no-cache nginx bash curl
COPY --from=builder /etc/startup.sh /etc/startup.sh
COPY --from=builder /etc/mimir/mimir.yml /etc/mimir/mimir.yml
COPY --from=builder /etc/nginx/nginx.conf /etc/nginx/nginx.conf
COPY --from=builder /etc/nginx/authnginx/htpasswd /etc/nginx/authnginx/htpasswd
COPY --from=mimir-binary /bin/mimir /bin/mimir
RUN chmod +x /etc/startup.sh
USER 0
EXPOSE 9010
ENTRYPOINT ["/etc/startup.sh"]
Deployment von Mimir
Nun haben wir alle wesentlichen Komponenten für das Deployment vorbereitet. In diesem Kapitel möchte ich nun meine Empfehlung zur Reihenfolge des Deployments vorstellen.
1. Schritt: Deployment der benötigten Azure Infrastrukturanteile
Entsprechend unserer Architekturzeichnung solltest du bereits das VNet inkl. der erforderlichen Ressourcen wie Subnetze, Container App Environments, Private Endpoints, Storage Accounts und Key Vaults deployt haben.
2. Schritt: Deployment von Memcached
Als erste Ressource unserer Setups solltest du Memcached deployen, da diese keine harten Abhängigkeiten besitzt und unabhängig von den anderen Ressourcen bereits deployt werden kann. Du musst im Rahmen des Mimir Deployments zusätzlich die FQDN der Memcached Container App referenzieren, sodass diese idealerweise bereits existieren sollte.
3. Schritt: Deployment von Consul
Consul ist unsere Basis für den Mimir Hashring. Mit diesem Hashring wissen wir zu jedem Zeitpunkt wieviele Mimir Instanzen zur Verfügung stehen. Die einzelnen Mimir Komponenten der jeweiligen Replikas koordinieren sich zudem über diesen über Consul bereitgestellten Hashring.
Wie bei Memcached müssen wir auch die FQDN der Consul Container App vor dem Start der Mimir Instanzen referenzieren. Aus diesem Grund sollte Consul ebenso vor dem Start von Mimir erreichbar sein.
4. Schritt: Deployment von Mimir
Jetzt können wir mit dem Deployment von Mimir starten. Dabei musst du wie aus dem Startup-Skript für Mimir hervorgeht, die FQDN von Memcached, Consul, Storage Account und gegebenenfalls deines Key Vaults referenzieren.
Die Besonderheit dieses Mimir Setups ist nun, dass du für deine Mimir Container App je nach Anforderung die Anzahl der Replikas festlegen kannst. In unserem Beispiel haben wir drei Replikas geplant. Du musst jetzt nicht drei unterschiedliche Mimir Container Apps mit unterschiedlichen FQDNs deployen, sondern kannst die Replika-Funktion nutzen und die jeweiligen Replikas werden im Consul-Hashring registriert. Jedes Replika ist demnach durch Consul in der Lage den Workload zwischen allen Replikas aufzuteilen. Falls du in Zukunft Performance Spikes hast oder dynamisch die Anzahl der Mimir Replikas erhöhen möchtest, passt du dazu über die Container Apps Scaling Rules die Anzahl der Replikas an.
Probleme mit Mimir - Too many unhealthy instances in the ring
Nach dem vollständigen Deployment von Mimir und den dazugehörien Support sind wir grundsätzlich fertig, aber es existieren im Monolithic Deployment dennoch Probleme die es präventiv zu lösen gilt.
Das Redeployment Problem
In verteilten Systemen wie Grafana Mimir ist Zuverlässigkeit der Knoten entscheidend für die Stabilität des Gesamtsystems. Ein bekanntes Problem tritt auf, wenn Container in Umgebungen wie Azure Container Apps abstürzen oder neu gestartet werden.
Die zugehörigen Instanzen bleiben im Hashring (bzw. Memberlist) als unhealthy markiert. Dies kann zur Folge haben, dass Distributoren, Ingester oder die restlichen Mimir Komponenten fehlerhaft arbeiten oder sogar der gesamte Datenfluss gestoppt wird, obwohl genügend gesunde Knoten vorhanden wären.
Administratoren müssen dadurch manuell mit Hilfe der Mimir Api eingreifen und die toten Einträge im Ring entfernen. Ein sehr fehleranfälliger und aufwändiger Prozess, besonders in größeren Clustern oder bei häufigen Deployments.
Die Grafana Community schlägt dabei vor eine Funktion einzubauen, die automatisch ungesunde Member im Hashring nach einer definierten Zeitspanne vergisst. Grafana Loki implementierte ein ähnliches Feature bereits erfolgreich.
Leider existiert diese Funktion leider nur für Distributoren, sodass für alle anderen Komponenten von Mimir mit Hilfe der Mimir API die "unhealthy" Instanzen aus dem Hashring entfernt werden müssen. Falls diese fehlerhaften bzw. veralteten Mimir Instanzen nicht aus dem Hashring entfernt werden, kann dies dazu führen, dass in Grafana keine Queries ausgeführt werden können.
Eine eigene automatisierte Lösung implementieren
Um dieses Problem zu lösen, möchte ich in diesem Kapitel ein Skript bereitstellen. Dieses Skript kannst du in Gitlab oder Github im Rahmen eines Scheduled Jobs verwenden und damit kontinuierlich sicherstellen, dass alle Mimir-Komponenten zuverlässig funktionieren.
#!/bin/bash
# Funktion zur Überprüfung des Mimir Health Status
check_health() {
echo "Überprüfe den Health Status von Mimir..."
# Sende eine HTTP-Anfrage an den /ingester/ring Endpoint und speichere den HTTP-Statuscode
http_status=$(curl -s -o /dev/null -w "%{http_code}" \
-u "$MIMIR_USERNAME:$MIMIR_PASSWORD" "$AZURE_MIMIR_FQDN/ingester/ring")
if [ "$http_status" -eq 200 ]; then
echo "Health Status erfolgreich. HTTP-Status: 200"
return 0
else
echo "Health Status fehlgeschlagen. HTTP-Status: $http_status"
return 1
fi
}
# Definiere die maximale Wartezeit und den Intervall für wiederholte Checks
max_wait_time=240 # Maximale Wartezeit in Sekunden
check_interval=30 # Intervall zwischen Prüfungen in Sekunden
elapsed_time=0 # Bereits verstrichene Zeit
# While-Schleife, um auf gesunden Mimir Health Status zu warten
while [ $elapsed_time -lt $max_wait_time ]; do
if check_health; then
echo "Mimir Health Status ist OK."
break
else
echo "Mimir Health Status ist nicht OK. Neue Prüfung in $check_interval Sekunden..."
sleep $check_interval
elapsed_time=$((elapsed_time + check_interval))
fi
done
# Wenn Mimir innerhalb der maximalen Wartezeit nicht gesund wird, Skript beenden
if [ $elapsed_time -ge $max_wait_time ]; then
echo "Mimir wurde innerhalb der erwarteten Zeit nicht healthy. Skript wird beendet."
exit 1
fi
echo "*** Starte Forget-Skript für unhealthy Mimir-Instanzen. ***"
# Hole den aktuellen Status des Ingester-Rings
response=$(curl -s -u "$MIMIR_USERNAME:$MIMIR_PASSWORD" "$AZURE_MIMIR_FQDN/ingester/ring")
# Extrahiere den Bereich mit unhealthy Instanzen
unhealthy_section=$(echo "$response" | grep -A 8 'UNHEALTHY') || unhealthy_section=""
if [ -n "$unhealthy_section" ]; then
# Suche nach Instanznamen, die mit "ca-" beginnen und bereinige die Ausgabe
unhealthy_instances=$(echo "$unhealthy_section" | grep -o 'ca-.*' | \
sed 's/" type="submit">Forget<\/button>//')
if [ -n "$unhealthy_instances" ]; then
echo "Unhealthy Instanzen gefunden:"
echo "$unhealthy_instances"
else
echo "Keine Instanzen gefunden mit Präfix 'ca-'"
fi
else
echo "Keine unhealthy Instanzen im Response gefunden."
fi
# Wenn keine unhealthy Instanzen gefunden wurden, Skript beenden
if [ -z "$unhealthy_instances" ] || [ "$unhealthy_instances" = "" ]; then
echo "Keine unhealthy Instanzen gefunden."
exit 0
fi
# Für jede unhealthy Instanz den Forget-Request an verschiedene Komponenten senden
for instance in $unhealthy_instances; do
echo "Löschen der unhealthy Instanz: $instance"
curl -s -u "$MIMIR_USERNAME:$MIMIR_PASSWORD" "$AZURE_MIMIR_FQDN/ingester/ring" -d "forget=$instance"
curl -s -u "$MIMIR_USERNAME:$MIMIR_PASSWORD" "$AZURE_MIMIR_FQDN/distributor/ring" -d "forget=$instance"
curl -s -u "$MIMIR_USERNAME:$MIMIR_PASSWORD" "$AZURE_MIMIR_FQDN/store-gateway/ring" -d "forget=$instance"
curl -s -u "$MIMIR_USERNAME:$MIMIR_PASSWORD" "$AZURE_MIMIR_FQDN/compactor/ring" -d "forget=$instance"
curl -s -u "$MIMIR_USERNAME:$MIMIR_PASSWORD" "$AZURE_MIMIR_FQDN/query-scheduler/ring" -d "forget=$instance"
done
echo "Alle unhealthy Instanzen erfolgreich gelöscht."
Mit diesem Mechanismus sollten deine Mimir Instanzen zuverlässig funktionieren und auch bei einem Redeployment oder das Reduzieren der benötigten Mimir Instanzen die Verfügbarkeit gewährleistet sein.
Falls du mehr über dieses Problem erfahren möchtest, kann ich dir dieses Github-Issue empfehlen. -> Link zum Github-Issue
Mein Fazit des Scalings des Monolithic Modes
Damit möchte ich diesen etwas längeren Blog-Beitrag mit meinem Fazit abschließen. Mimir ist ein unabdingbarer nächster Schritt, um deine Metriken aus Prometheus, Pushgateway etc. langfristig verfügbar zu machen.
Mit diesem Blog-Beitrag solltest du nun verstanden haben, dass man für Mimir nicht zwangsläufig den Microservice Deployment Mode benötigt und trotzdem von mehreren Mimir Instanzen profitieren kann. Natürlich ist Mimir nicht perfekt und besitzt zum gegenwärtigen Zeitpunkt einige Kinderkrankheiten. Es kann sich trotzdem lohnen die Verwendung von Mimir in Erwägung zu ziehen.
Da ich mich aber besonders auf die Azure-nativen Lösungen spezialisiert habe, werde ich im Rahmen meines nächsten Blogartikels dir auch eine Azure-native Lösung vorstellen. Diese wird den Log Analytics Workspace mit Custom Data Collection Rules und Endpoints nutzen und als effektive Alternative zu Mimir für Grafana Daten dienen. Der Vorteil ist dabei ganz klar die Performance, da der Log Analytics Workspace serverless ist und Azure meiner Meinung nach die Aggregierung, Bereitstellung und Abfrage von Metriken und Logs effizienter handhabt als Mimir. Für ein gleichwertig performantes Mimir Setup benötige ich eine hohe Anzahl an Mimir Instanzen, welche allein aus Kostengründen nicht rechtzufertigen ist.
Hilfreiche Links für weiterführende Recherchen
- Mimir Deployment Modes: https://grafana.com/docs/mimir/latest/references/architecture/deployment-modes/
- Komponenten von Mimir: https://grafana.com/docs/mimir/latest/get-started/about-grafana-mimir-architecture/
- Erwähnte Github Issues: